1. 변수와 확률변수
(1) 변수
변수란 숫자로 표현된 정보 중 그 값이 변화하는 것
▶ 양적변수 : 숫자로 표현할 수 있는 변수(ex. 시험성적, 키, 몸무게 등)
▶ 질적변수 : 범주로 나타낼 수 있는 변수, 범주를 숫자화하여 보여줄 수도 있음(ex. 남자는 1, 여자는 0)
(2) 상수
상수란 경우에 따라 변화하지 않고 고정되어 있는 값
(3) 확률변수
- 확률변수의 정의 : 무작위 실험을 하는 경우 특정 확률로 발생하는 각각의 결과를 수치로 표현한 변수
- 예를 들어, 주사위 하나를 던질 때 발생할 수 있는 경우는 1, 2, 3, 4, 5, 6인 6가지인데, 이 6가지 경우를 확률변수라고 하며, 6가지 사건의 집합이 표본공간임
2. 이산형 확률변수와 연속형 확률변수
(1) 이산형 확률변수
- 변수가 취할 수 있는 값이 이미 정해진 숫자만 취할 수 있는 경우의 변수(ex. 주사위)
- 이산점에서 0이 아닌 확률값을 가지며, 각 이산점에서 확률의 크기를 표현하는 함수를 확률질량함수라고 함
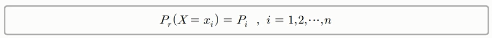
(2) 연속형 확률변수
- 변수가 취할 수 있는 값이 어느 정해진 구간 안의 어떤 임의의 값이라도 취할 수 있는 경우의 변수
- 특정한 실수 구간 내에서 0이 아닌 확률값을 가지며, 이 구간에 대한 확률함수 f(x)를 확률밀도함수라고 함
3. 확률분포
(1) 이산확률분포
1) 이산확률분포의 특징
- 정수와 같은 비연속적인 값에 대한 분포
- 두 확률변수 값 사이에 중간 값은 존재하지 않음
- 수직 막대그래프의 모양으로 표현함
2) 베르누이(Bernoulli) 분포
- 변수 x가 가지는 값이 0과 1뿐으로서 아래와 같은 식의 함수를 가질 때 변수는 베르누이 분포를 따름
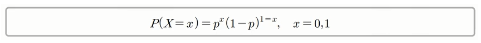
- 예를 들어 불량품이 20%인 어떤 생산 공정에서 1개의 제품을 검사하여 불량품이면 변수 X=1이며, 정상품이면 X=0으로 나타낸다면 위 식에 따르면 다음과 같이 표시함
P(X=0) = 0.8 = 1-P, P(X=1) = 0.2 = P
- 베르누이 확률분포의 평균과 분산

3) 이항분포
- 한정된 시행횟수 중 특정한 사건이 발생하는 횟수를 나타내는 분포
- 이항분포의 조건 : 시행시에는 2가지 결과만 나올 수 있음, 사건 발생이 서로 독립적, 특정 사건이 발생할 확률은 각 시행시마다 동일함
- 성공 확률 p, 성공 시행횟수 X, 총 시행횟수 n, 시행횟수 k라고 할 때 이항확률변수를 수학식으로 표현하면 아래와 같음

4) 포아송(Poisson) 분포
- 정해진 시간, 거리, 혹은 장소에서 발생하는 특정한 사건의 횟수에 대한 분포
- 기본조건 : 임의의 구간에서 발생하는 사건의 수 제한 없음, 사건 발생이 서로 독립적, 평균 사건 발생 수는 매 구간에서 동일
- 특정한 사건이 평균 μ회 발생할 때 해당 사건이 k번 발생할 확률을 수학식으로 표현하면 아래와 같음
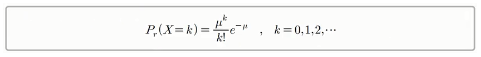
- 예를 들어 어떤 사무실에 1시간 동안 평균 3번의 전화가 걸려올 때, 각 상황별로 확률을 구하기 위한 파이썬 코드는 아래와 같음
예시) 1시간에 1번 전화가 걸려올 확률
[파이썬 코드]
from scipy import poisson
poisson.pmf(1,3, loc=0)
예시) 1시간에 2번 이상 전화가 걸려올 확률
[파이썬 코드]
from scipy import poisson
1-poisson.pmf(1,3, loc=0)
(2) 연속확률분포
1) 정규분포
- 정규분포는 좌우대칭이며 종모양을 하고 있으며, 평균(μ)과 표준편차(σ)로 모양이 결정되고 이 때의 분포를 N(μ, σ2)로 표기함
- 표준정규분포는 평균이 0이고 표준편차가 1인 정규분포임
- 수리적으로 정규함수로부터 유래한 분포이며, 반대적인 개념이 비정규라는 의미는 아님
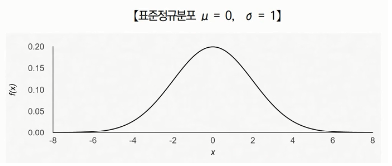
- 정규분포에서 확률변수 X의 확률밀도함수는 아래와 같음

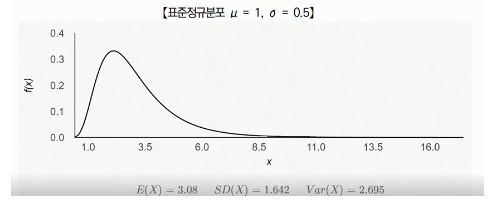
2) 로그정규분포
어떤 확률변수 X의 로그 값이 정규분포를 이룰 때 X의 확률분포는 로그 정규분포를 따름
KICPA ALLDEMY(https://kicpa-alldemy.com/)의 재무빅데이터분석사2급 강의자료를 학습하고 정리한 글임을 미리 알려둡니다.
'빅데이터분석' 카테고리의 다른 글
| [기초통계학] Chapter 4. 확률 (2) | 2024.01.10 |
|---|---|
| [기초통계학] Chapter 3. 기술통계분석 (1) | 2024.01.01 |
| [기초통계학] Chapter 2. 자료의 척도와 형태 (1) | 2023.12.29 |
| [기초통계학] Chapter 1. 통계학이란 무엇인가? (1) | 2023.12.29 |



